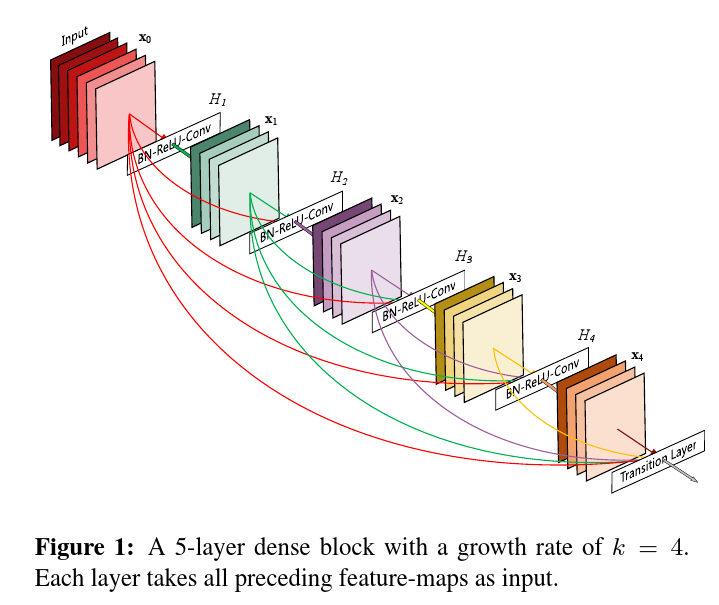
DCNN发展概述
DCNN的发展过程,离不开ImageNet比赛。而每次新的网络结构的出现,也会刷新ImageNet的精度。DCNN作为深度学习中使用率最高的网络结构,相应的研究也比较成熟,因此可以从其本身的发展来观察深度学习进化的脉络。
最早的CNN网络结构和BP思想早在1985年就提出,但第一次在图像分类上进行应用还是LeNet的工作。
LeNet
1998年的LeNet标注着CNN的真正面世,但是这个模型在后来的一段时间并未有很多关注。LeNet能够在MNIST数据集上得到不错的效果,但由于计算能力的限制,很难应用到其他数据集上。而此时网络的精度,和传统的统计机器学习模型(如SVM、KNN)能够达到的精度相同,此外由于模型的不可解释性,LeNet一直没有进入主流视线。
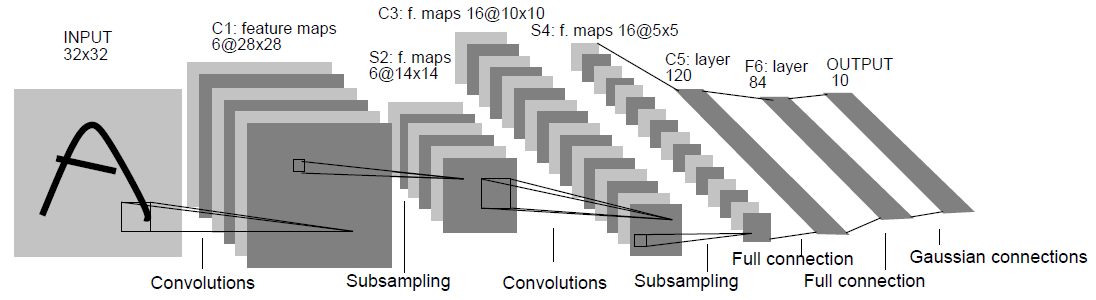
上图为LeNet的网络结构,从中可以看出其模型使用了卷积和pooling以及全连接等结构,足以看出结构的雏形。
AlexNet
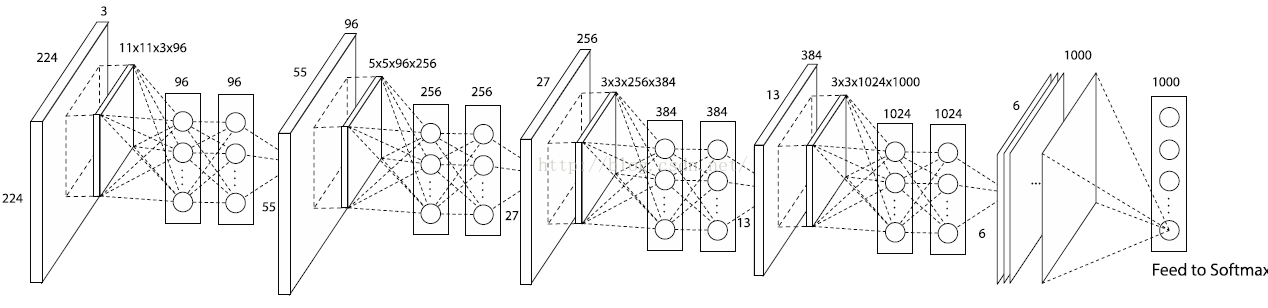
2012年出现的AlexNet是首个进入大众视角的网络结构。AlexNet网络在ImageNet比赛拿下第一名,并传统方法数十个百分点,也是首个成功应用与自然图像分类的网络结构。
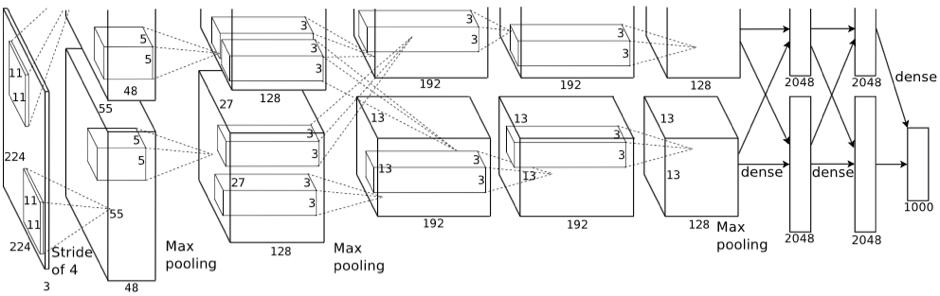
上图为AlexNet网络结构,受限于显存大小,网络卷积由两个GPU完成,并在全连接阶段进行拼接。我们可以看出AlexNet网络和LeNet网络在结构上非常类似,结构次序上也是卷积、pooling和全连接的结构。
AlexNet网络贡献主要有如下几点:
- 引入数据扩充操作;
- 加入了Dropout;
- 使用Relu替代Sigmoid;
- 加入了Normalization层;
VGG
2014年出现的VGG网络,同样也采用了类似的网络结构,但在卷积大小和网络深度上进行一些实验。VGG具体结构如下:
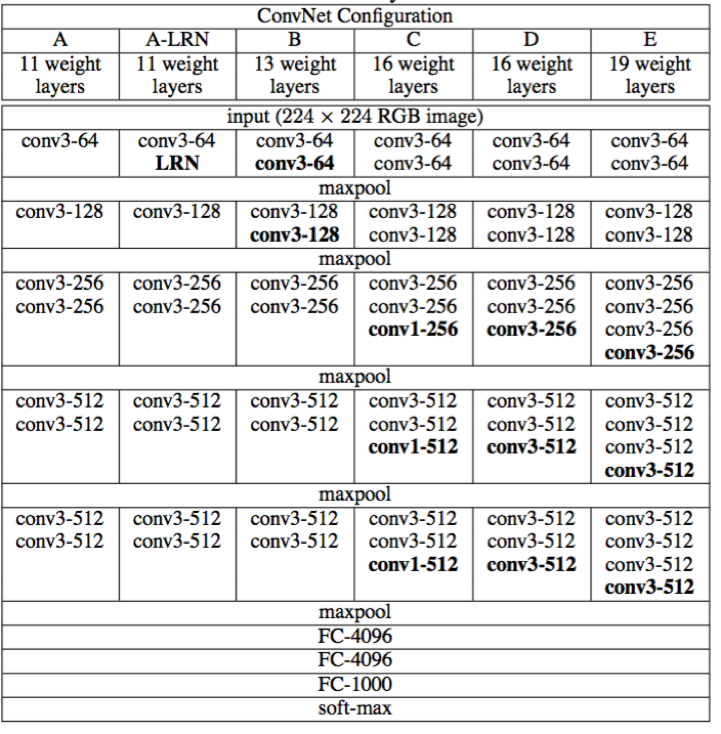
VGG网络贡献主要有如下几点:
- 证明小的卷积核能够保留更多信息;
- 证明网络越深拟合能力越强;
此外由于VGG网络结构和精度的提高,VGG网络结构被广泛应用于图像领域的各个任务(如物体检测、图像分类等),提高了相应的精度。由于VGG网络的成功,证明了越深的网络拟合能力越强,人们开始尝试更深的网络,但此时的网络结构已经非常臃肿,很难进行扩展。
在上述三个网络结构中,我们可以看到一个共同点,三者的网络结构都是先使用若干个卷积层,再使用若干个全连接层。试图通过卷积层完成特征提取,使用全连接层来完成特征分类的操作。但是全连接层的参数众多,占据了网络参数的绝大部分,所以研究者开始思考,网络参数缩减的问题。
Network in Network
从VGG开始,人们开始尝试各种新颖的网络结构,想用更小的网络来获取更好的精度。2014年的Network in Network(NIN)网络,就是其中的一项工作。
NIN网络基于以下思路:包含VGG网络和之前的网络,在卷积层提取的特征是类似先行的特征,网络卷积特征没有非线性。因此NIN提出了MLPCONV结构,在原有的卷积层之间加入类全连接的结构,提高了网络的非线性,如下图所示。
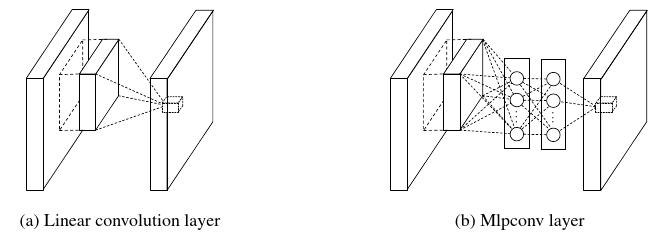
NIN在卷积的内部,对每个卷积层的通道加入了对应的全连接层,可以理解为对每个卷积层都进行了特征提取和分类的操作。NIN网络采用全局均值池化的方法,替代传统CNN中的全连接层。采用均值池化,可以减小网络避免过拟合;另外NIN每张特征图相当于一个输出特征,特征就表示了我们输出类的特征。如果做1000个分类任务的时候,最后一层的特征图个数就要选择为1000。NIN网络结构如下图:
GoogleNet
GoogleNet和VGG是2014年ImageNet竞赛的双子星,与VGG不同,GoogleNet受NIN网络的启发,设计并尝试了新的网络结构。
实践证明网络的深度和卷积感受野的宽度,会给网络带来更好的性能。而神经元信息的稀疏性也表明,分析激活值的统计特性和可以逐层构建出一个最优网络。GoogleNet在提出了新的Inception模块,因此又称为Inception网络,结构如下图所示:
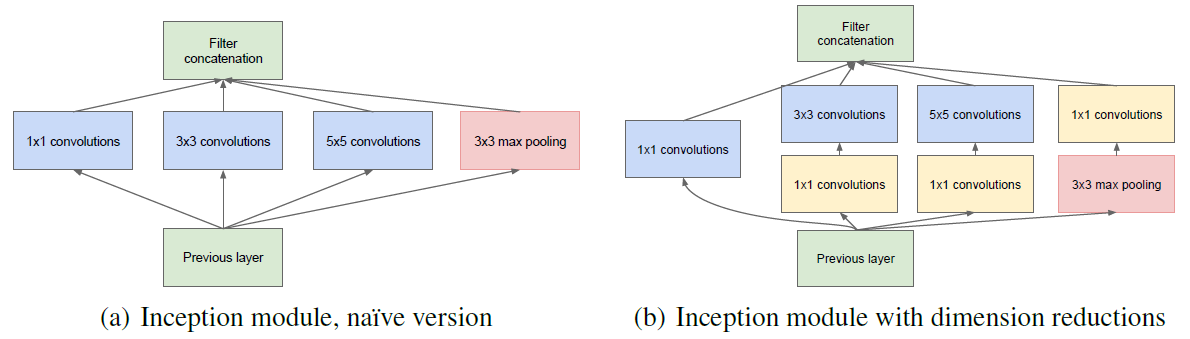
Inception通过不同的卷积核设置不同的卷积步长,将不同视野的卷积特进行了拼接。GoogleNet还在网络的上加入了几个softmax输出,设计在不同深度的网络层上,以此解决梯度消失的问题。
Inception结构的发展,不断刷新了我们对网络结构的认识,至今有四个版本:
- Inception v1的网络:将1x1,3x3,5x5的conv和3x3的pooling,拼接在一起,增加了网络的宽度,也增加了网络对尺度的适应性;
- Inception v2的网络在v1的基础上,方面了加入了BN层,用2个3x3的conv替代inception模块中的5x5;
- Inception v3一个最重要的改进是将7x7分解成两个一维的卷积(1x7,7x1),3x3也是一样(1x3,3x1),加速计算,也使得网络深度进一步增加,增加了网络的非线性,还有值得注意的地方是网络输入从224x224变为了299x299;
- Inception v4研究了Inception模块和ResNet参差模块进行结合,提升了性能和也加快了训练速度;
ResNet
深度学习网络的深度对精度有很大影响,理论上越深的网络性能越好。但是事实上在网络很深的时候,效果却越来越差了。 这里原因之一是网络越深,梯度消失的现象就越来越明显,网络的训练效果也不会很好。 但是浅层网络很难明显提升网络精度,所以要解决的问题就是怎样在加深网络的情况下又解决梯度消失的问题。
2015年出现的ResNet主要的创新在残差网络,网络本质还是要解决层次比较深的时候无法训练的问题。ResNet网络借鉴了Highway Network思想的网络相当于旁边专门开个通道使得输入可以直达输出,而优化的目标由原来的拟合输出H(x)变成输出和输入的差H(x)-x,其中H(X)是某一层原始的的期望映射输出,x是输入。ResNet网络结构如下图:
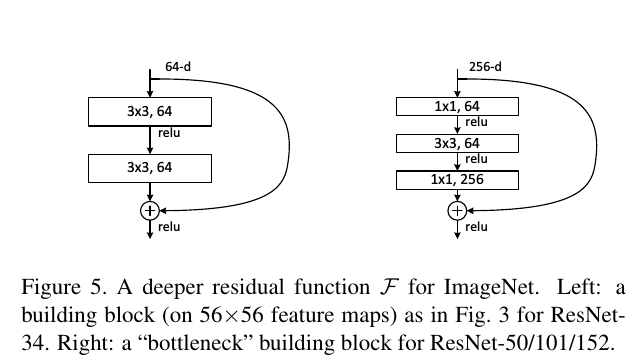
ResNet网络有多种解读方式,其中可以从模型融合的角度来进行思考。残差网络单元其中可以分解成右图的形式,从下图中可以看出,残差网络其实是由多种路径组合的一个网络:残差网络其实是很多并行子网络的组合,整个残差网络其实相当于一个多网络投票系统。
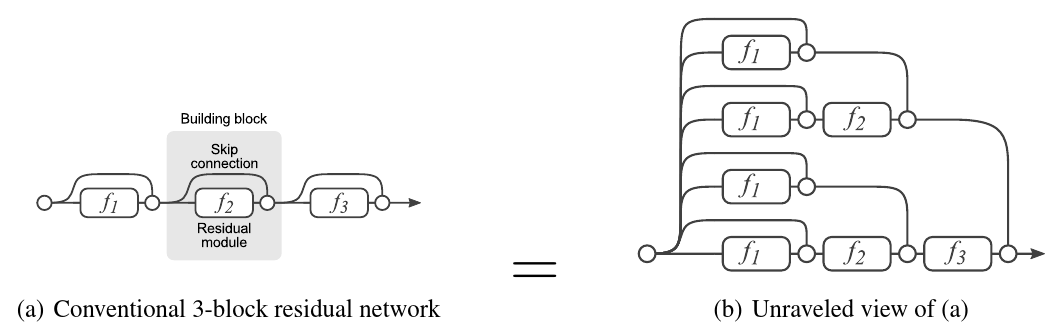
从此角度可以进一步探讨网络的内部结构:
- ResNet网络的平均网络深度集中在20-30层;
- ResNet网络删除中间层,并不会对精度带来很大影响;
之后借助ResNet网络和Inception结构,出现了很多以此类想法进行改进的模型,如ResNeXt、DenseNet和Duall Path Networks,其思路都是设计具有更加非线性拟合能力的网络结构模型。