参加完中诚信征信公司举办的首届”风云杯机器学习建模比赛,成绩不错同时也在实践的过程中收获颇多。由于举办方不允许公开比赛代码和文档,因此我将从参赛体验和参赛过程两个方面大概总结下本次比赛。
参赛过程
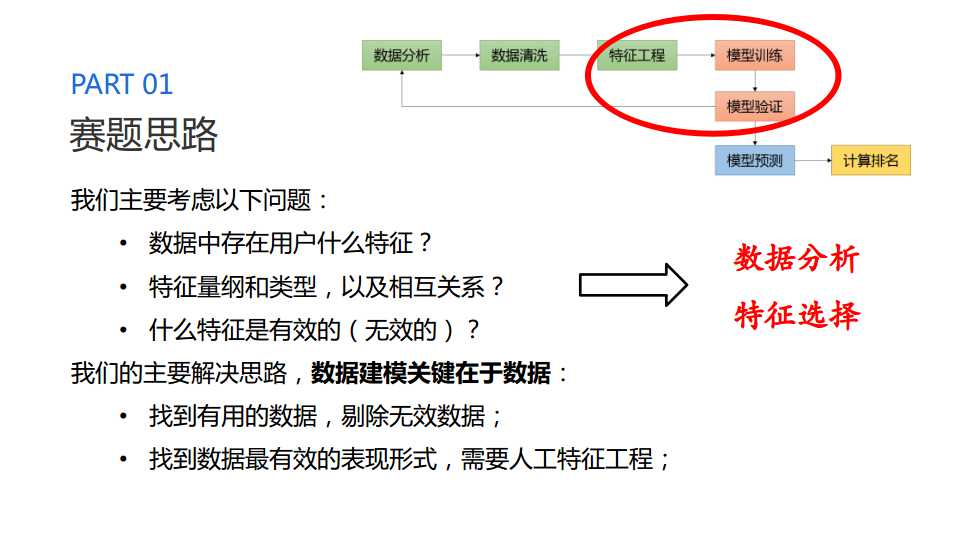
分析比赛数据
拿到比赛数据之后,发现数据只有一个表,且已经为我们提取好了特征。原始数据的特征维度,已经高达5百多维度,且特征变量类型匿名、量纲不统一、缺失验证。这也是本次比赛的主要难点,需要通过具体的分析数据来解决。

在具体的进行数据分析之前,我们要弄清楚我们现有的是什么样的数据,比如数据的训练集和测试集是不是同分布的、数据特征的缺失有什么规律、数据特征的具体分布等。这一点非常重要,因为我们需要拟合的是测试集,不是训练集,所以我们一定要保证训练集和测试集是同分布的。
分布数据特征
接下来我们要做的是分析比赛的数据特征,对每一维度的特征进行具体分析,这里要结合特征的分布、取值结果、说明和类型来分析,这一步骤的主要任务是对特征进行了解。但是我在做的过程中,只是对特征的类型和含义进行了大致的猜测,并没有人为对特征进行重要性划分。
通过对特征进行具体分析,我们可以找到缺失太多的特征、方差太小(变化幅度不大的)特征以及分布不一致的特征。前两种操作我想很容易理解,但本次赛题数据中有很多分布不一致的特征,这个分布不一致指特征在训练集和测试集上面分布不一致(比如特征1在训练集取值0和1,但在测试集只取1),此类特征对模型影响较大,容易导致过拟合。

构建模型
本次赛题数据不知道特征含义,所以很难提取有效的特征。因此可以优先将构建模型,方便进行特征选择。这里选择了XGB,因为数据缺失和量纲的考虑。由于本次赛题数据的原因,构建模型并不是精度差别的主要来源。

提取特征
提取特征步骤,我首先提取了地理位置特征(经纬度、城市分级)。并结合特征的类型,对特征的进行对特征进行提取了违约率排名等。最后结合可视化,提取了二元交叉特征。提取的特征要保证有效,就要使得特征能够提高本地AUC,这一步骤就行需要具体训练模型。
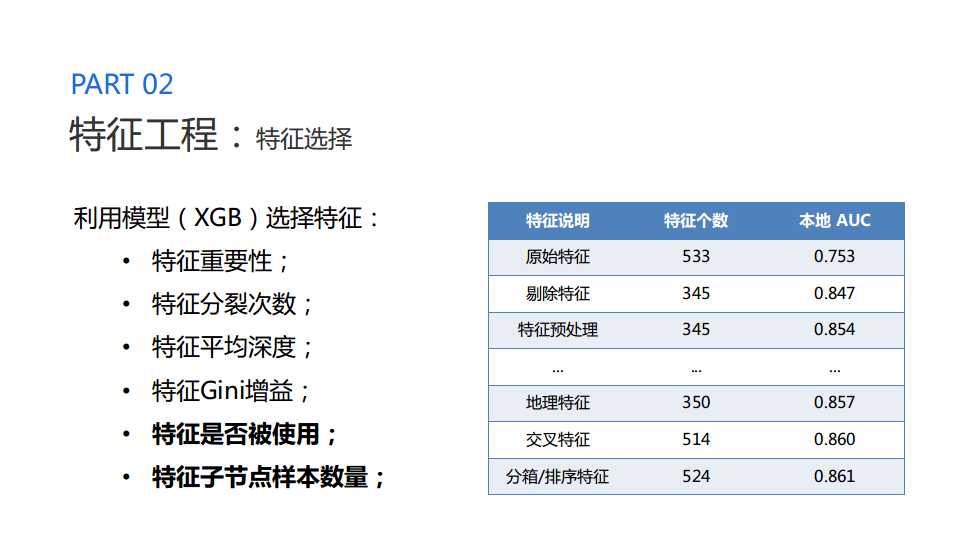
特征选择
充分利用XGB模型来筛选特征,并结合可视化筛选二元交叉特征。推荐使用xgbfir包可以加将XGB模型的特征进行有效排序,并进行输出。
参赛总结
赛题难点
赛题难点主要集中在数据特征的匿名上,难以进行提取特征和清洗特征。但本体大部分选手都都没有进行很好的清洗特征(特别是职业信息),导致了模型过拟合。如果数据清洗做的比较完好,那么得到的成绩不会太差。
还有一个难点集中在提取特征上,地理位置信息和二元交叉信息确实很有价值,对精度帮助很大。当然提取有效的特征确实比较花费时间,首先要想到提取的方式,同时也要保证提取的特征能够提高精度。
赛题总结
- 做好文档记录并写好文档。并行化操作,保证结果可复现。
- 赛题难点:数据清洗、特征工程;
Have fun!
