论文介绍
论文RCNN来自Ross Girshick,作者也是在传统物体检测领域非常有名气,也用深度学习的方法彻底改变了物体识别和分割领域。论文发表在CVPR2014,是首个将深度学习成功应用到物体识别的工作。之后的识别方法发展也是借鉴了RCNN的思路,所以RCNN在物体检测领域,算是深度学习方法的开山之作,以后的方法都要与它进行精度和运行效率的比较。
论文内容
物体识别(检测)和图像分类不同,其更加细致,需要模型输出物体具体类别的同时,也要给出物体在原图中的位置。如果将物体的bounding box与CNN结合,就得到本文的RCNN方法。RCNN(Regions CNN),通过名字就可以看到,它是基于区域的CNN。
RCNN解决识别的方法为:通过传统方法得到proposal,大小归一化后利用pre-train的CNN得到特征,再对特征进行分类。可以看到RCNN是还是需要借助传统物体检测方法,来得到潜在边框。
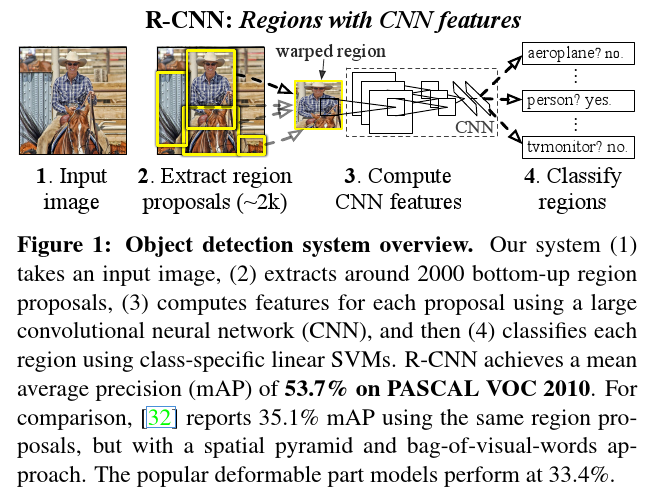
Objection Detection with RCNN
此部分讲解了RCNN的具体方法和流程,选择Selected Search作为生成proposal的方法,利用SVM对提取的特征进行one-vs-all训练。
- 提取CNN的网络使用的是AlexNet,先在PASCAL上fine-tune下;
- 每幅图片生成2000个左右的proposal,再分别使用AlexNet提取特征;
- SVM训练过程中需要考虑边框位置,可以对边框进行回归;
Semantic Segmentation
由于语义分割的一个步骤就是物体检测,因此RCNN也将方法在分割上进行试验。但此处需要注意的是,RCNN只能输出矩形边框,并不能对输出像素级别的结果。因此RCNN分割试验,只是为了说明其检测结果的优越性。
论文创新点和问题
论文是首个将CNN网络应用到物体检测中的工作,将物体检测的精度直接提高了几十个百分点。
总体上说论文有如下创新点:
- 更新了物体检测方法的思路;
- 树立了一个物体检测方法的实验标准;
同时由于论文模型使用了很多中间结果,需要在过程中间保存等,导致模型在预测阶段比较慢。
- 一张图片,可能有2000个proposal,每个区域都需要提取CNN特征;
- 需要训练多个SVM分类器;
论文评价
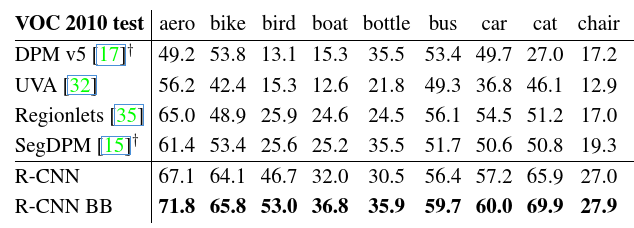
首先论文的文笔和应用的参考文献非常充实,每个实验对比都有明显的提高;其次论文的思路非常明确,解决的思路也比较清晰,可以进一步发展。论文在分析结果中也指出,物体检测精度的提高主要来自CNN模型,而主要误差来自于提取proposal的方法。