赛题分析
第三届安全赛以病毒API检测为主题,比赛提供了win32程序在沙箱中运行的API序列信息,赛题本质任务是根据程序序列进行多分类任务。
数据分析
比赛提供的数据非常规整,根本不需要进行其他的预处理操作。
如图所示赛题数据按照文件file_id进行组织:每个文件file_id对应一个文件标签,即文件的病毒标签;每个文件file_id可能由一个或者多个线程tid组成。每个线程tid由一个api或者多个api组成,每个api对应一个返回值,api的次序关系由index表示。
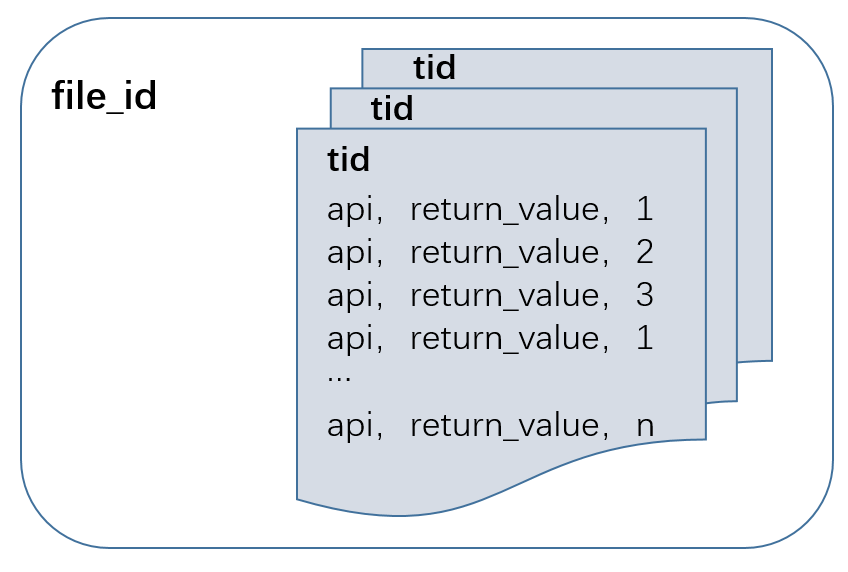
赛题数据中,不同线程tid之间没有顺序关系,同一个tid里的index由小到大代表调用的先后顺序关系。index是单个文件在沙箱执行时的全局顺序,由于沙箱执行时间有精度限制,所以会出现一个index上出现同线程或者不同线程都在执行多次api的情况,可以保证同tid内部的顺序,但不保证连续。
初赛的训练数据大概是,训练集11w条程序记录,测试集5w条程序记录。6类程序中正常程序特别多,病毒程序偏少。
特征工程
我们将本次赛题视为一个文本分类问题,即通过API序列和API返回值序列来对程序进行分类,判断其是否为病毒程序。因此我们在构建特征工程的过程中借鉴了文本分类的思路,通过API序列和API返回值序列来构建模型。如果将一个程序记录是为一篇文章,则每个tid记录为一个段落,每个API序列和API返回值为一个词语。
但在探索数据的过程中,我们发现程序api序列与文本分类数据有一定差异性,其中也代表了程序序列的特征:
- 程序API序列中API存在多次重复和反复调用的过程;
- 程序API序列中API的返回值反应了api的执行结果;
- 程序API序列执行有一定并发性和随机性;
综上所述,我们将从三个角度提取特征:
- 统计特征:统计API的出现次数、类型统计以及API返回值的统计特征;
- 图模型特征:将API序列转换成API图的边,统计有向图的相关的特征;
- 时序特征:API序列的出现次数等时序特征,API返回值的时序特征;
统计特征
根据我们对数据的理解,我们从三个维度提取的了统计特征:file_id维度、tid维度和api维度。按照此种思路我们提取了的以下特征:
| 特征维度 | 特征含义 |
|---|---|
| file_id维度 | tid个数 |
| file_id维度 | tid长度 |
| file_id维度 | |
| tid维度 | tid中api个数 |
| tid维度 | tid中api取值数 |
| tid维度 | |
| api维度 | api范围值非零的个数 |
| api维度 | api范围值非零的比例 |
| api维度 |
同时我们将API进行了分类,从功能上将API分类:注册表、网络、内存、文件、服务、进程、DLL、加解密、搜索文件、控制台、设备、套接字、错误异常、Ldr、资源、Hook、系统信息和Buffer等类别。进而统计了file_id的功能使用情况,并做了相应的统计特征。
- 注册表api:RegOpenKeyExW、RegQueryValueExW、RegCloseKey等
- 网络api:InternetOpenW、InternetConnectA、InternetReadFile等
- 内存api:NtAllocateVirtualMemory、WriteProcessMemory、CryptProtectMemory等
- 文件api:NtCreateFile、NtWriteFile、NtQueryAttributesFile等
- 进程api:CreateThread、Thread32First、Thread32Next等
- 服务api:OpenServiceA、CreateServiceA、DeleteService等
- 加解密api:CryptAcquireContextW、CryptProtectMemory、CryptUnprotectMemory等
- COM组件api:CoCreateInstance、CoCreateInstanceEx、CoGetClassObject等
- Hook api:SetWindowsHookExA、SetWindowsHookExW、UnhookWindowsHookEx等
时序特征
在分析病毒API的工程中,我们发现不同的病毒的API一定的周期性。因此我们抽取每种病毒的公共API序列作为特征,并提取了序列的重合程度等特征。
其次还可以对API序列提取TFIDF特征,提取API的ngram特征。这也是本次赛题的关键特征,前排队伍都有相应的操作。ngram可以表征API序列的出现次数,比如高频特征以及长尾特征。
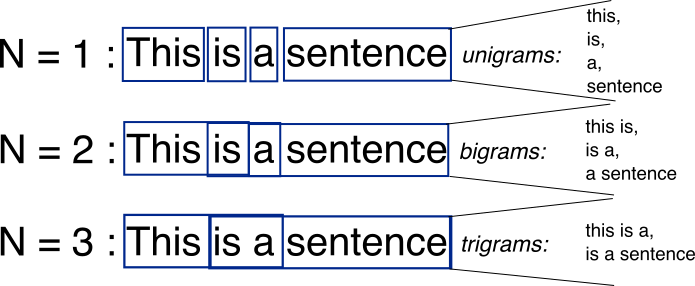
在提取ngram过程中,可以截取ngram,也可以不进行截取。如果截取则ngram可以保证维度比较低,有效保证特征维度较低;如果不进行截取,则可以保留长尾特征,但特征维度较高。因此ngram可以用不同的参数提取,得到不同的结果,用来进行stacking。
在分析病毒API序列的工程中,我们发现病毒的API序列同时也存在较为明显的重复规律。因此我们抽取每种文件的API前后各1000长度序列作为cnn的网络输入特征,这样的特点是便于我们发现以及提取病毒序列在开始和结束的时候调用api的特点。
构建模型
模型包括LightGBM和NN两个模型:
- LightGBM
- 统计特征+2ngram
- 统计特征+3ngram
- 统计特征+4ngram
- 统计特征+5ngram
- 统计特征+2ngram+3ngram
- 统计特征+2ngram+3ngram+4ngram
- 统计特征+2ngram+3ngram+4ngram+5ngram
- NN
- 主线程API2VEC + CNN/RNN
- 前后API2CEV + CNN/RNN
此外本次赛题stacking收益极大,GBM和NN缺一不可。
赛后思考
- 本次赛题的初赛分数分布差异很大?
- 一方面是由于stacking的原因,stacking收益大;
- 另一方面可以通过调分布,获得一定收益;
- 如何高效提取特征?
- 可以提前将csv按照程序分到文件,多线程提取;
- ngram没办法并行,所以需要高配机器;
云溪大会-现场赛
现场赛数据和初赛基本一致,唯一的区别是剔除了返回值列。数据量也比较小,但由于现场赛时间比较有效,需要在6小时内跑完单模型,然后进行stacking。
现场赛当然是跑着代码,玩手机啦~

